











To roughly quote the movie Field of Dreams, “If you build it, they will come.” Once you empower content authors’ creativity with hero sections, calls to action, buttons, card galleries, forms, and more, they will take advantage of your tooling to create flexible landing pages that drive sales to your business. Within a month, you could have hundreds of new pages, each of which contain a button that says, “Try it now.”
And that’s a good thing.
What’s not a good thing?
Making content authors wade through 300 CMS elements pointing to various URLs, all titled “Try it now.”

As a developer, building components feels great. It’s The Life-Changing Magic Of Tidying Up, for your HTML. Instead of managing a 500-line page layout file, you break your codebase into organized folders full of 20-line component files like card.js, button.js, and form.js.
But “more documents” isn’t always better in your content store.
Clutter or controlled chaos?
Take a look at index.md from our guide How to Separate Content from Website Code. There are over 60 lines of YAML, including the types of list-of-object data I described before (one for “speakers” and one for “FAQs”).
Arguably, if this page were tied to the larger CMS for a web site dedicated to a given conference, breaking out each speaker into a standalone file might make sense, to facilitate building 1 URL per speaker bio.
But if this is the landing page for a one-off event, steering visitors’ clicks to a Hopin registration portal? Perhaps those speakers’ names will never be mentioned on the company site again. Arguably, the CMS shouldn’t be cluttered for the rest of time with one standalone record per speaker.
Our favorite modeling decision tree
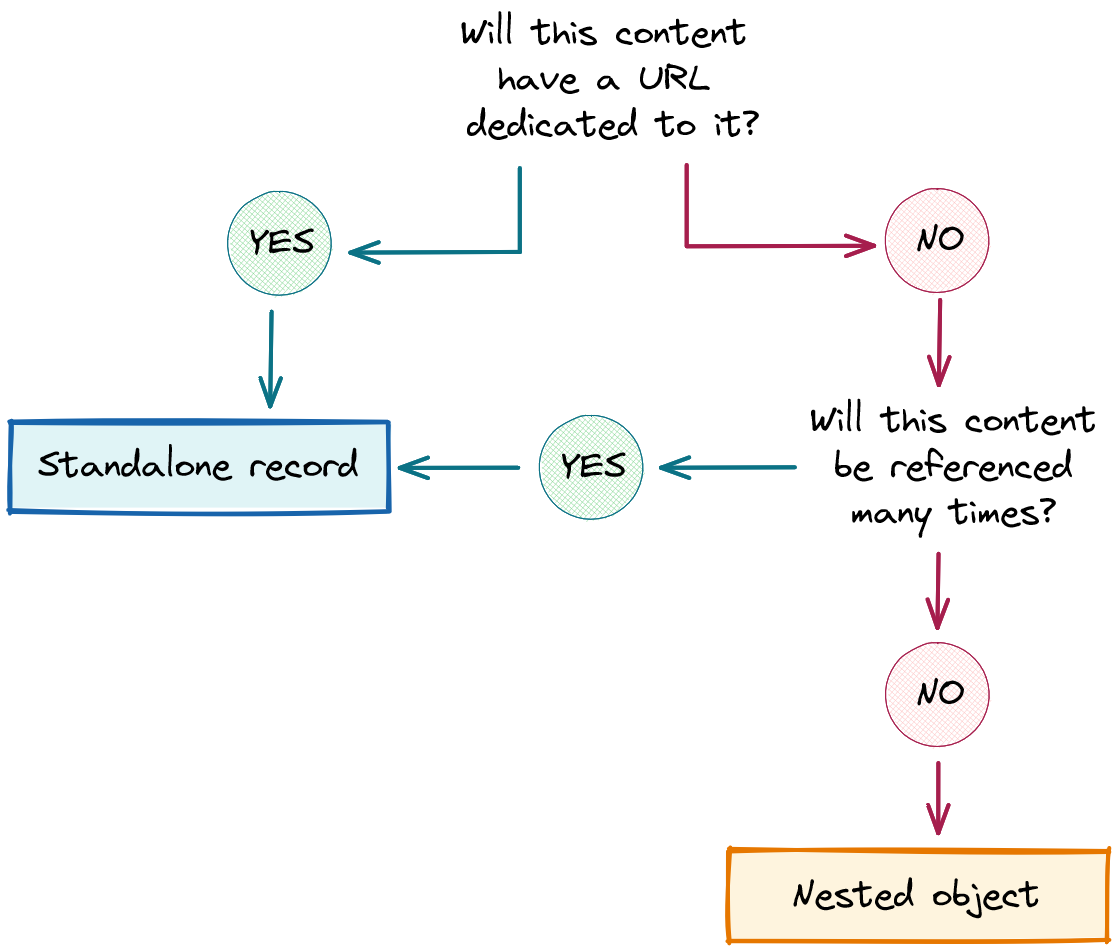
As a rule of thumb:
If you’re modeling object-shaped content where each item will become a URL, make each object a standalone record in your CMS.
In Git-based content management, this would likely be an entire file.
In headless API-based CMS, the system might call this a “document” or simply a piece of “content.”
If you’re modeling content that will be referenced repeatedly from other content (e.g. the “venue” for a musician’s concert calendar), make each object a standalone record in your CMS.
In Git-based content management, cross-reference documents using their file path, or if that doesn’t work for your project, some other property you are careful to keep unique.
Otherwise, simply nest the item’s content directly inside its parent object’s data store. The long index.md file we looked at earlier is a good example of this for git-based content. Some API-based CMS also support this pattern — e.g. DataCMS calls it “modular content,” Sanity uses “object.”
Tidying up is magic!
When you model top-level CMS records judiciously, you end up with tidy, well-organized datasets powering the flexible page-building experiences that content authors rely on. When designing a content schema, the approach to relating objects to one another is both challenging and crucial. This is how we think about object relationships in website content schemas.
