











For better or worse, many of the mental models that we bring into Jamstack development come from the traditional CMS world, and from Wordpress in particular. Take the case of content modeling. This was largely an afterthought in Wordpress since it defaulted to some basic - and largely unstructured - content types: the post and the page.
The thing is, this worked well, as Wordpress (and most traditional CMS systems) had only one intended result: the web page. Unstructured content fit this purpose and gave content writers the flexibility to create just about anything within the confines of the post and page content models. Even today, the Wordpress API is built to deliver rendered HTML. But unstructured content has limitations, which is why Wordpress ACF (advanced custom fields) has become a ubiquitous add on.
The Jamstack is, obviously, still about building outputs for the web, whatever the form factor, but one of its key selling points is its decoupled nature. In the case of content, the frontend of a Jamstack site is decoupled from the backend headless content management system (CMS). One key benefit of this is that the content can be reused in multiple different sites, a mobile app, a chat app, a voice-enabled app, etc. This means a more thoughtful approach to content modeling is needed, but, in many cases, we default to the largely unstructured post and page model of Wordpress.
In this post I want to explore why content modeling is important in the Jamstack and how to approach content modeling for headless CMS.
What is a Content Model?
A content model is a diagram of your content universe. It describes the various content types that comprise your content, lists their content attributes and shows how the various types relate to one another.
Let's take a very simple and common example. Imagine I am responsible for a very simple blog wherein all of my content are blog posts, with each post having an author. My simple content model might look something like this:
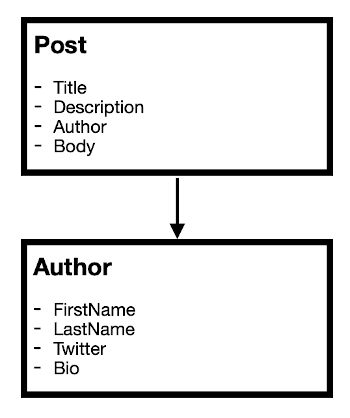
For anyone used to database modeling, this may seem somewhat familiar but less granular (we aren't focused on things like primary keys, data types, length and so on). In this case, we just have two content types - a post and an author. Each post contains a reference to an author. This is very simplistic and you can already imagine I might expand this with things like a category type that also relates to post. Or my post may have related posts wherein the post type references other instances of a post.
Most content models won't be as simple as the one shown above. For instance, let's see a slightly more complex example that consists of posts with authors but also events. Each event can have multiple sessions and each session can have one or more speakers. However, in this case not only is the information that I need for a speaker largely the same as the information that I need for an author, but it is also entirely possible that someone could be both an author and a speaker. Preferably, we'd want to avoid duplicating this information in our CMS, so abstracting both speaker and author as person would allow us to reuse that in both the relationship with sessions and with posts.
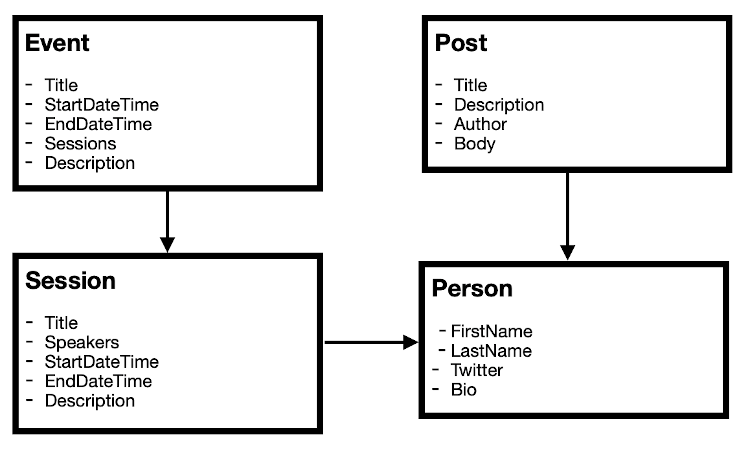
Without thinking through a content model, abstractions like the author/speaker one shown in the example above be get easily overlooked during development. Refactoring an existing content model can often be very painful (I know this from personal experience), so planning can save you a lot of time and effort down the road. This is also why it is important not to think of it purely as a description of the pages of your website, even if that may be its primary use initially. Keep in mind that this content may be used in any number of destinations.
I highly recommend reading Content Modelling: A Master Skill by Rachel Lovinger for A List Apart. It gives an excellent overview of concepts and considerations that expand upon the topics covered here.
Unstructured Content Versus Structured Content
Thinking only about a web page output will also lead to the overuse of unstructured content. Unstructured content can lead to maintainability problems down the road.
To illustrate what I mean, let's imagine the events site again. Thinking in terms of purely a web page, you might come up with something like this, whereby your event has a title, startDateTime, endDateTime and then a body that represents the remainder of the page content.

The benefit here is that the content editor has almost unlimited flexibility in how the event description and schedule is laid out. However, after the page is up, perhaps we decide it is probably worth having pages for each author and session. Or, even worse, after we've done a ton of events, we decide that we want to change the layout of the all the events to be consistent to help avoid confusion. In each of these cases, our unstructured page content means that we'll have to make some painful changes to our existing content model and manually fix each instance of an event.
The better approach, illustrated in the model from the prior section might look something like this.

Since session and speaker are now separate content types, we can easily manage the layout to be consistent across pages and create separate pages for each session and speaker. Plus, we can now use the same content to populate our event's mobile app without duplicating the effort!
For a deeper look at structured content, read Strategies For Headless Projects With Structured Content Management Systems by Knut Melvær of Sanity.
Balancing Developer Wants with User Needs
While structuring your content can be hugely beneficial for things like flexibility, reuse and long term maintainability. It does come with some tradeoffs. The more you abstract your content model by separating things into distinct content types, the more steps you create for an author/editor who wants to create content.
For example, despite its issues, the unstructured event page we discussed earlier would be fairly simple to create, and involve just one step. The unstructured version would involve multiple steps, some of which themselves are made up of multiple steps:
- Add each individual speaker;
- Add each individual session and associate the speakers with the session;
- Add the event and associate each individual session with the event.
In this case, this is a worthwhile, in fact necessary, tradeoff. In some cases though, the additional complexity from a content creation and editing standpoint may not be worth the potential benefit of further abstraction.
As a simple example, sometimes you may want to separate out image objects that are used for things like headers as a separate content type.
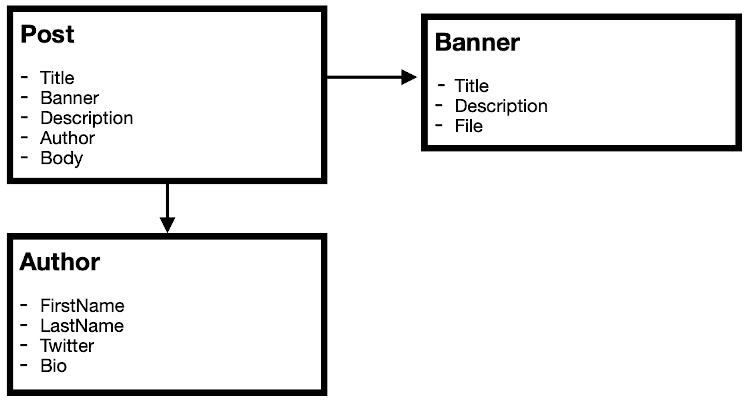
This can be very useful if these banners are likely to be reused across multiple posts or included in other types of content, especially as it allows the custom title and description fields to populate the img properties without cluttering up the post attributes. However, if these images are specific to a post, it can be cumbersome to have to create a separate image object when the image could be a single property of a post and the img properties could reuse the title and description from the post.
Finding this balance can be difficult but the point is not to go overboard abstracting out content types.
Content Models in Headless CMS
One of the benefits of creating a content model is that it can make the process of setting up your headless CMS much more straightforward. How that happens depends largely on the headless CMS you choose (and there are a lot of great options).
In a git-based headless CMS, you'll generally be translating your content model into a combination of Markdown, YAML and JSON. In some cases, you'll need to directly map these individual content types and content attributes out in a configuration file (for instance, this is required by Netlify CMS but only necessary for granular control of the content model in Forestry). One aspect that isn't necessarily obvious, though, is managing content type relationships in a git-based system. Planning your content model ahead of time can save you a ton of frustration. I can attest from personal experience that adding or updating attributes can, in some cases, require a lot of manual file editing.
How you configure an API-based CMS based upon your content model depends largely on which one you are using. In systems like Contentful, for instance, content models are built using a web-based UI. In others like Sanity, they are configured with code.
For example, here is the simple post content type shown above configured in Contentful.
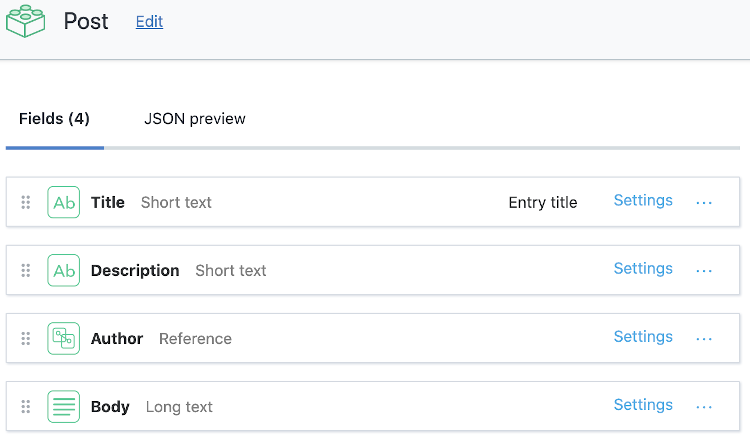
Meanwhile, in Sanity the code representing the same content type is:
{
title: "Post",
name: "post",
type: "document",
fields: [
{
title: "Title",
name: "title",
type: "string"
},
{
title: "Description",
name: "description",
type: "text"
},
{
title: "Author",
name: "author",
type: "reference",
to: [{type: 'author'}]
},
{
title: "Body",
name: "body",
type: "text"
}
]
}Managing relationships between content types in an API-based CMS is built into the system, and there are protections to maintain the integrity of the data. For instance, in the above example, by default I will not be able to delete an author that is referenced in an instance of a post.
While the specifics of how the content models are created may change across tools, the benefit of planning ahead with a content model can save a lot of time in development and prevent painful modification to a content model after the content has already been populated.
Summing Up
Developing a content model will save you time and effort when configuring your headless CMS and prevent costly mistakes down the road. If done early in the planning process, it can help define the constraints for design and user experience, inform your technology choices and help clarify business goals. The best part is, content models don't have to be compilcated to be useful. Simply establishing your content types, attributes and relationships is enough. There's no need to necessarily dig deep into data types or validations at this point.
One final point is that this should not simply be a developer task. A content model is more likely to be accurate and successful if it involves people from across your organization - in particular those who will be responsible for writing and editing different aspects of the content (both written and media assets). So involve stakeholders from marketers to content writers and designers whenever possible. A look at why content modeling can be important in a Jamstack context, where headless content management systems rule, and some best practices for creating a content model.
