











The JAMstack coupled with a headless CMS is a powerful combination. It offers the speed, security and development experience benefits of JAMstack on the frontend, while still providing the content management experience on the backend that content authors and editors need.
Still, there are a number of stumbling blocks or "gotchas" you may encounter when developing your site. Part of this is due to the decoupled nature of the architecture. For example, while you can do anything with your frontend as it's not tied directly to the backend, that can also lead to issues when someone managing the content modifies a content model or edits content in a way that the app isn't designed to handle. In this article, I want to share some "best practices" our team at Stackbit has learned through experience working on these sorts of sites.
I want to acknowledge that this article is based heavily on insights shared with me by our amazing engineering team at Stackbit and, in particular, with the assistance of David Berlin.
Handle Invalid CMS Content
The ease of editing experience in a headless CMS offers a great deal of flexibility to your content editors. This is part of what makes these systems compelling. But this means that sometimes the content you receive on the frontend may not arrive as you'd planned - perhaps an attribute is missing or doesn't have the type of value you typically expect. Let's look at some strategies and example code for handling unexpected or invalid content.
Ensure Validation on the CMS Side
Every CMS option offers tools for validating input. The best way to ensure you don't receive invalid content on the frontend is to prevent it being entered in the backend.
Contentful has a list of available validations. Any field can be marked as required, but which additional validations are available largely depends on the type of content. For example, a date field can be limited to a specific range of dates.
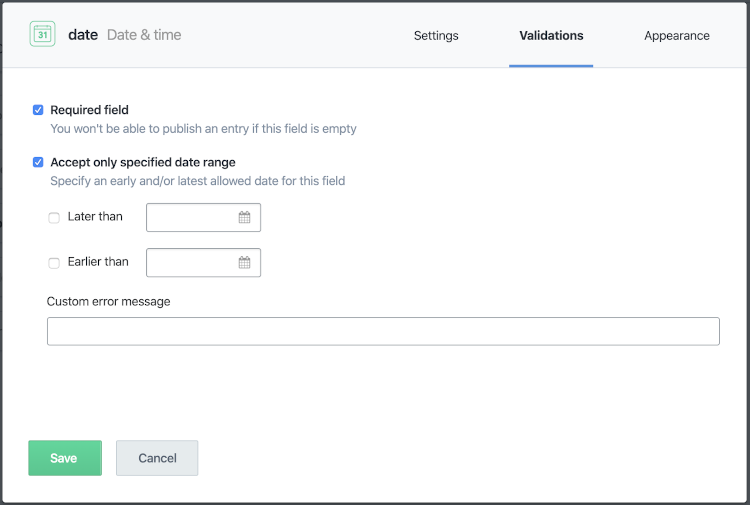
In Sanity, the validations are added as code within the schema file. The benefit of this is that it allows for very customizable, fine-grained validations. However, regardless of which headless CMS option you choose (and there are many), ensure that you do whatever it permits to prevent erroneous data making it to the front end.
Output Valid Content on the Client-side
We'll talk more about handling changes to the underlying data structure in the next section, but here we're talking about what happens if improper data makes it through to the frontend. There are three scenarios to think of:
- Preventing the display of invalid data
- In many cases, invalid data won't cause a complete failure at build time, but it may end up getting displayed to the user, which is something you will want to avoid. This is something that can typically be handled in code (for instance for React-based tools like Gatsby or Next.js) or using the SSG's templating language like Liquid for Jekyll or Hugo templating for Hugo that provide conditionals, functions and filters.
- Preventing build errors due to failed queries
- In some cases, as with some of the JavaScript-based solutions, you'll be loading content via an external API call, perhaps using GraphQL. Misaligned data can cause an
unknown fielderror or a type checking failure.
- In some cases, as with some of the JavaScript-based solutions, you'll be loading content via an external API call, perhaps using GraphQL. Misaligned data can cause an
- Preventing issues in previews
- In most cases, data validations on the CMS side are not performed on draft content. Therefore if you rely upon the APIs for retrieving draft content to display previews, you may encounter missing or erroneous data when attempting to use a template to preview draft content.
The best way to handle many, if not most, of these issues is to code defensively, so let's discuss that.
Code Defensively
As we noted in the prior section, content models may change or disappear or you may be attempting to preview a draft that has not been run through validation. These can cause your site build to fail if not properly accounted for and can lead to major headaches. The way to deal with that is to write a "defensive app" that can handle these changes without failing.
- Don't assume fields exist or have a valid value
- Trying to output a null or empty field can result in errors or just unpredictability in how content displays. Pretty much every static site generator (SSG) offers tools for determining if a value exists, ensure that your templates code around this possibility. Aside from being empty, you may receive fields whose values may be unexpected. This is especially true if you are displaying draft previews as even required fields may not have a value or may have invalid values since they may not have been run through validation in the CMS.
- Don't assume linked objects exist
- Most CMS provide a way of linking objects within the CMS. For example, in Contenful these are links and in Sanity they are called references. However, it isn't always safe to assume that because an object is linked in the record, it actually still exists within the CMS.
But how can you code defensively when dealing with these sorts of issues. Here are some tips.
First, use conditional rendering to determine if the conditions are met before displaying content. For example, here's how to do conditional rendering in React, but templating for other SSGs offer similar capabilities.
Second, leverage tools that can simplify data access in complex structures. For example, in JavaScript-based tools you can use lodash's get function. Other tools provide similar functions like default and isset is Hugo.
Third, avoid tight coupling by normalizing data as much as possible in the data layer. If you are using React, you would likely create a data layer within React that would handle any data interactions (here's an 8 part series on creating a data layer in React). If you are using something like Hugo or Jekyll, your data layer could exist within serverless functions that call the API and populate the content within your build process. This data layer will ensure that data is passed consistently and you are protected (as best you can be) from changes in the underlying content model, irregular or missing data in a response or changes to the API.
Leverage the Existing Ecosystem
Developers love to create - it's part of what drives us. Generally, this is great, but it can sometimes lead to a "reinventing the wheel" syndrome. The JAMstack ecosystem isn't always the easiest to navigate, which can amplify the desire to roll your own solution,. Still, this can lead to problems in multiple ways, from not using the best practice methods provided by your particular toolset to not keeping up with potentially breaking changes within updates in your stack. Let's look at some examples of how you can do better by leveraging the tools provided the ecosystem around your chosen stack.
Where there is an existing ecosystem of tools to assist, it's almost always recommended to use them. They enforce best practices for both the SSG and the CMS, use the appropriate endpoints in the API, make data available in a consistent manner, and understand complex object relationships within the CMS (rather than you having to write the code to handle that).
For example, Gatsby has a source plugin for Contentful, for Sanity, for DatoCMS and more. In cases where there isn't an existing ecosystem of plugins, there may be community tools that you can leverage, but they'll require more effort to vet that they actually enforce best practices. At Stackbit, we released a tool that can help with this called Sourcebit which connects the CMS API with the SSG and has existing plugins for Contentful and Sanity on the CMS side and Hugo and Jekyll on the SSG side (for more on how to use Sourcebit, check the introductory tutorial).
Conclusion
Decoupled architectures using a headless CMS offer a ton of benefits. The frontend or the backend can be upgraded without impacting the other. CMS APIs can be accessed from a variety of frontends, whether they are web, mobile apps, voice assistants, chat, etc. Plus, they allow us to leverage the JAMstack and all of it's benefits. But decoupled architectures also bring in new considerations that may not have existed previously. Following some best practices when working with a CMS and a SSG can take some additional up-front work. However, in the long run, it'll save you a ton of headaches. There may be stumbling blocks when connecting a JAMstack site to a API-based headless CMS and, in this post, we'll look at what these are and how to mitigate them.
