











Intro
Twitter's tech stack of today is a huge beast, so any attempt at a quick "Can't you just use X to solve problem Y at Twitter scale?" risks being pretentious and ignorant. Many engineers spent years making the critical pieces scalable and fault-tolerant. This is the main reason why the service is still online today.
But, as geeks, it's always a good thought experiment to try and figure out: which approaches would work at this scale? Which won't? And which are easier to scale or make more resistant to failures?
The first service I want to consider is serving the Home timeline to users fast and at scale. Arguably, this is the tip of the iceberg.
There are many other components to Twitter, of course. Consider notifications, search, real-time analytics, or ads with all their internal and external-facing elements. Each involves serving in real-time, big data analytics, relevant ML models, monitoring, and an ongoing effort to squeeze better KPIs with ever-more-complex methods.
Off-the-shelf solutions never "just work" at a social network scale. They need meticulous tuning, at the very least - if not significant improvements and customizations. By the end, you essentially get a new product. Even the seemingly-simple task of counting likes gets more challenging at scale (but that's a topic for another post).
So, let's start with the timeline, then. And one disclaimer: I'm going to make a whole bunch of assumptions along the way.
Narrowing down the problem
To greatly simplify the problem, I'll focus here on how to fetch the timeline by chronological order (a.k.a. Latest tweets) rather than tackling "Top tweets," which is the default.
There are two reasons for skipping "Top tweets": first, it complicates things further. Second, the Top tweets algorithm is, or at least was, fundamentally a re-ranking problem over the X latest tweets. It is a mechanism sitting on top of the latest tweets query.
Let's also ignore everything about the ads, suggestions, and myriad other things that get mixed into a user's timeline. Each of these is provided by a dedicated service that needs an engineering team to build, optimize, scale, and debug.
What we know: the numbers
What's the approximate number of timeline requests in a day? We know that Twitter has nearly 500 million Daily Active Users (DAU), but only roughly half of these are considered monetizable - what Twitter calls mDAU. It may suffice to assume that this service is called a few dozen billion times a day.
The total number of requests only tells part of the story, though. Knowing the distribution of some critical parameters also matters a lot. For example:
How often are requests made for the most recent tweets vs. earlier periods? This may affect our design and is greatly affected by client-side caching behavior.
How many accounts do users follow? The number of accounts a user can follow is capped at 5,000. That's valuable to know, but what's the actual distribution for the number of followed counts?
A Pew Research article from 2019 estimates that for the top 10% of tweeters (those who tweet the most), the median is 456 accounts. For everyone else, the median is 74. These top 10% of tweeters may refresh their timeline more than others, meaning that they'll be over-represented in calls to the timeline service. To account for that, I'll put the median of followed accounts per call at ~140.
Of course, Twitter wants to keep these top 10% happy, so the service has to work fast enough for them as well.
What we know: it was (and is?) fanout-on-read
Over the years, Twitter has publicly shed some light on successive iterations of its platform, but I did not find an up-to-date and well-sourced article on how timelines are served.
Here's what I did find:
In 2012, Raffi Krikorian (@raffi) gave an excellent presentation at QCon, describing how Redis was used as a timeline cache. Essentially, whenever a user makes a tweet, that tweet's ID is added to a cached timeline object for every one of their followers. This makes writes heavy but reads simple. Here's a snippet from the slides which captures that concisely:
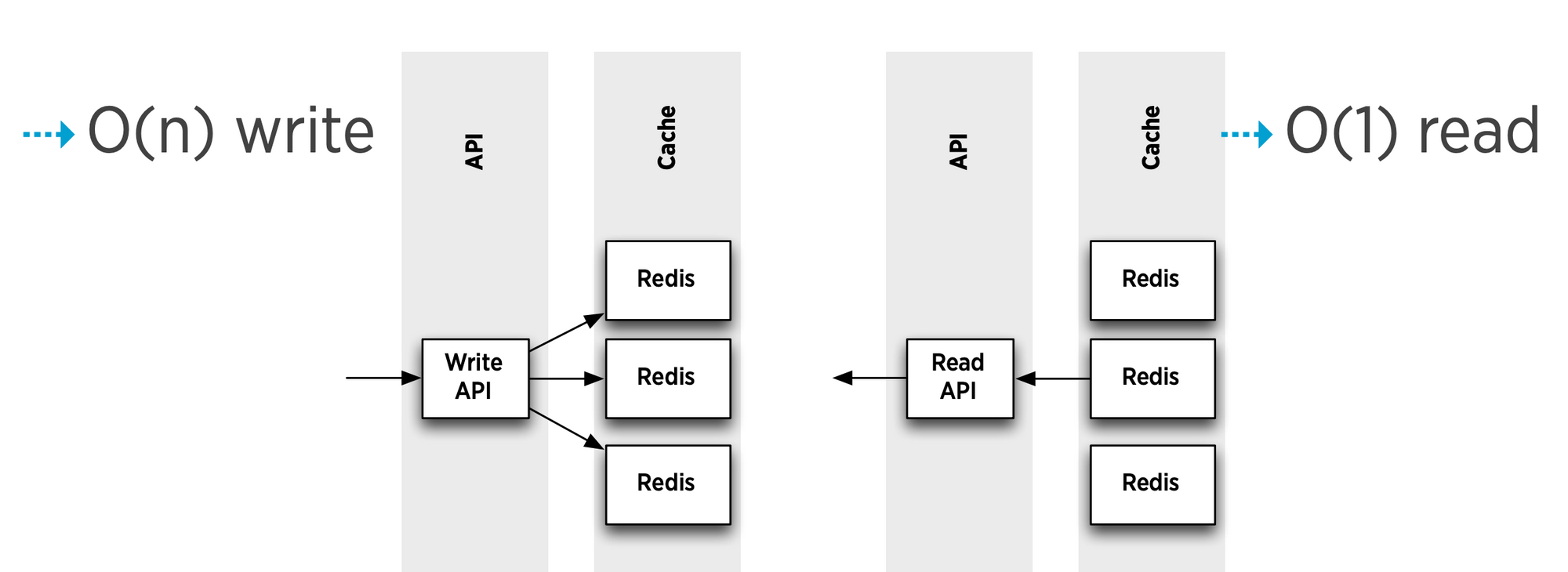
This design is a conscious choice to accept very high write amplification for popular accounts, for a major advantage at read time in return. If only I could shake out the picture in my head of DJT's infamous "covfefe" tweet inserted into ~90 million timeline keys!
This implementation is anything but naive, though. It was accompanied by hard work on optimizing writes (by async pipelining) and RAM usage (by adding new data structures to Redis).
Twitter also needed to build its own clustering solution for Redis, as none existed at the time (I wonder how close are the largest "out of the box" Redis clusters of today to this size).
There's also an interesting post from about a year later pointing out that Facebook has taken the opposite approach - one that could be called fanout-on-read. They have decided to go for on-demand composition for the user's timeline rather than trying to pre-fill it.
In 2015, Yao Yue, a longtime cache expert at Twitter, gave a seriously in-depth presentation on scaling Redis at Twitter, with the timeline cache being the premier use case.
There's also a Usenix paper from 2020 co-authored by Yue. It describes the complex operations of the many use case-specific Redis & Memcached clusters at Twitter (which are still highly customized). However, the paper does not specify whether the timeline is still essentially fanout-on-write as before.
Should we take another path today?
If anyone who worked on this feature at Twitter gets to read this, I can see them thinking:
"Do you know how many people have come up with their oh-so-smart suggestions over the years? So thanks, but this component already works as it should. The costs and trade-offs are known, and our real problems are found elsewhere, e.g., network saturation, multi-cluster management, etc."
Reworking this feature may well be non-material for Twitter, which clearly has a working implementation. But how should we approach this challenge for a new Twitter-like network?
As with many problems, various "secondary" optimizations could be applied over the current solution to reduce some of the load. Most probably, multiple optimizations are already implemented at Twitter.
As a basic example, you could do fanout-on-write for all tweets except those from the top X tweeters, whose tweets could be kept aside and merged with users' pre-cached timelines at read time. That way, you don't need to put covfefe-like tweets in millions and millions of timelines (pun intended). I'm not the first to mention this idea, of course.
The thing about optimizations is they usually mean more logic and more moving parts. And more logic equals more bugs, so one has to tread carefully. What about genuinely on-demand timeline composition, then?
For this to be feasible, we'll need to quickly read & merge all tweets by followed accounts at the relevant time frame. This means that our cache(s) should be well optimized for these read patterns (e.g., by time-slicing user tweets lists to different keys). However, not making a read is way better than making even a fast one, so we'll want to reduce the number of needed reads as much as possible.
If we can efficiently check which of a user's followed accounts have actually tweeted in a given time frame, our servers will only need to read these accounts' tweets from cache. For short time ranges, we can expect the % of active accounts to be pretty low, so the number of cache reads can be significantly lowered - perhaps even by 90%?
Note that the "relevant time frame" for a timeline query is subject to various heuristics depending on the context, primarily because with an "infinite scroll" user experience, no exact number of items must be returned in each call to the servers. For example, the more accounts you follow, the shorter the time range the server might look at to fulfill the call. Meaning, developers have considerable leeway in tuning these parameters.
Which accounts have actually tweeted?
Given a user ID for which a timeline request is made, let's get the list of followed accounts first.
This looks like a single read. With 64-bit "snowflake" account IDs, the response size for the median of ~140 followed accounts is slightly over 1k. Given the upper limit of 5,000 follows, the maximum response size is ~40k.
Optimizations (e.g., compression) are also possible here, but is it worth the hassle? Unless the network bandwidth is an issue, probably not. With today's fast networks, this is much less of a problem than it was for Twitter 10 years ago.
With the list in hand, let's move to the next step: reducing this list to actual active users in the time range.
A Bloom Filter, or one of its modern alternatives, can be of good use here.
A quick recap: a Bloom Filter is a probabilistic data structure used for answering one question: does a given key exist in an underlying set?
Bloom Filters never respond with a false negative, but they do produce some false positives (i.e., returning that the member exists when it doesn't). The larger the filter's size, the lower the probability of errors. Thus, Bloom Filters are typically used as an optimization. Before making an expensive operation (e.g., reading from disk), check first in-memory in the filter whether a key exists. If you get a false positive, it only means some un-needed trips to the source of truth. This technique has been widely used in databases for many years, and researchers are still developing improved alternatives (e.g., at Meta).
For my analysis, I will go with the classic Bloom Filter. It serves as a good baseline for improvement, and there is abundant public know-how.
Putting Filters to Work
Two main components are involved:
A backend stream processor
The processor's job is to maintain a Bloom Filter of every user ID that's tweeted in a given time window and publish it when the window is closed. This is a classic task for stream aggregation frameworks such as Apache Flink et al.
Filters can be produced for various time lengths - e.g., the shortest filter represents 30 seconds, and the longer ones represent several minutes to hours.
Publishing a filter can be performed via Redis - serialize the filter and use PUB/SUB to notify of a new one being available, so clients can load the filter into memory immediately as it becomes available.
The timeline query servers
As new filters become available, the query servers load them to memory.
Then, given a timeline query, the server determines which relevant filter/s to look at, given the query's time range. The goal of having filters of varying time ranges is to be able to cover most queries with either a single or very few filters.
Using the filter, the list of followed accounts is narrowed to only those who've tweeted in the time frame, plus a very low overhead of false positives.
How big should the filters be?
Of course, a super low probability of false positives is desirable, but it's also good to have the most used filters to fit in a server's CPU cache rather than needing to access RAM.
Modern Intel server CPUs have 1.5MB cache per core, so a 16-core physical server gives you 24MB of shared cache (note that on cloud providers such as AWS, a 16 vCPU machine actually means 8 cores).
Let's play with the numbers a bit using a handy online calculator by Thomas Hurst.
For a filter representing 30 seconds of activity:
Given the typical rate of 6,000 tweets per second, the set of account IDs who've tweeted is capped at ~180k items (and probably close to that).
Inputting this set size and 1% probability of false positives in the calculator, we get a filter size of 210KB:
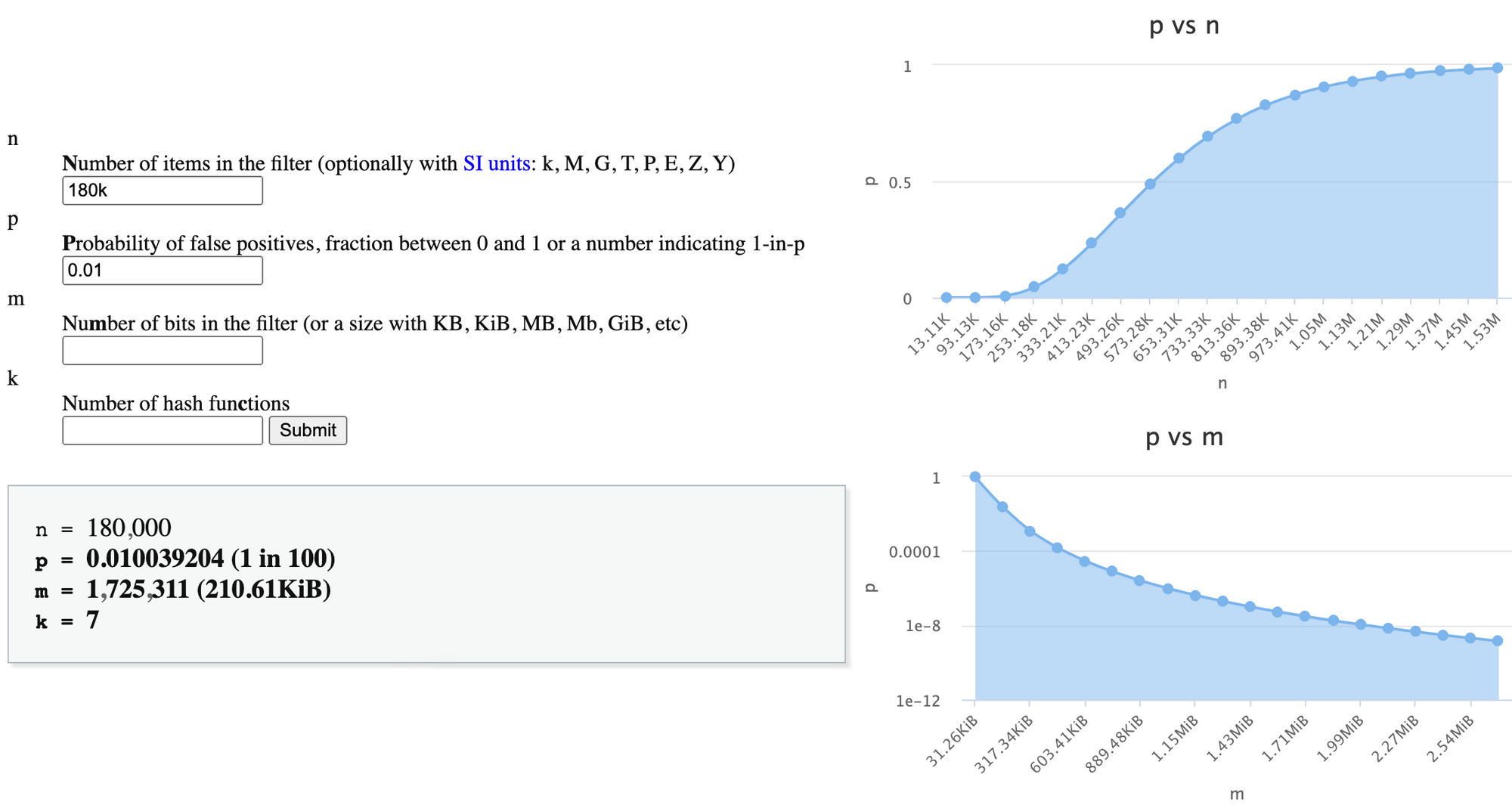
For the World Cup 2022 peak of 20,000 tweets/sec, the above filter size of 210KB for 30 seconds would yield a very bad p=0.5 (50% probability) of false positives. Aiming for a more reasonable 5% rate, we'll need a ~900KB filter.
For an hour of activity:
With the typical 6k tweets/sec rate, there are 21.6 million tweets an hour. What's the number of unique accounts that have made all these tweets, though? this ratio is very dependent on the duration. Let's assume these are made by 15 million accounts.
For 15 million items and a target 1% error rate, the size of a single filter should be 17.15MB.
Such filter sizes will not fit in the CPU cache, but hey - we could fit quite a few in RAM. In fact, 64 gigabytes of RAM can hold more than 150 days' worth of filters of this size.
Note that modern alternatives to the Bloom Filter are not only designed for better space efficiency but also to minimize memory access (e.g., Cuckoo Filter, Xor Filter).
Wrapping up
With the accounts that tweeted in hand, the tweet IDs of these users can be read from cache. The list of IDs might still be long, so batching is in order - and it needs to be aware of which shards the data is found. While in OSS Redis Cluster, these smarts are handled by each client, Twitter (and Enterprise Redis) have taken the proxy approach.
You will notice that even for this small (yet critical) piece of functionality for a Twitter-like network, there are a lot of questions, optimizations, and considerations to make. There's also a ton of work to build the infrastructure to serve this logic.
Along the way, I've made a lot of assumptions and conveniently avoided a lot of real-life requirements. However, I hope this article offers a glimpse into the type of challenges with real-time serving at scale.
The factors for picking the best solution for such challenges include more than raw performance. The tipping point is often found in other traits. Years ago, I was interviewed by the chief architect of a now multi-billion dollar company and presented to him a hard choice from my past. As the interview ended, he commented: "You know what's the best way to make such decisions? Pick the solution that's easier to test".
